1. Elasticsearch Basic Concept
Wiki:
Elasticsearch is a search engine based on Lucene. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
In my view, Elasticsearch is a kind of document-oriented NoSQL database which focuses on search. A record in Elasticsearch is managed by a JSON document. For instance:
{
"name" : "John Smith",
"sex" : "Male",
"age" : 28,
"birthDate": "1990/01/01",
"introduction" : "I love to go rock climbing",
"interests": [ "hiking", "music" ]
}
2. Index
In Elasticsearch, everything is for search. So the index is the most important part. But that also means that for search efficiency, some other operations, like insert, update and delete is low efficient. That’s the trade off. In Chinese, as the old saying goes, “鱼和熊掌不可兼得”.
2.1 Inverted Index and Posting List
Inverted Index is an index data structure storing a mapping from content to its location in a database file. An inverted index needs to map terms to the list of documents that contain this term, called a postings list
For example, we have a several data: | ID | Age | | – | — | | 1 | 24 | | 2 | 24 | | 3 | 29 |
Elasticsarch builds an inverted index like this: Age: | Term | Posting List | | – | ———— | | 24 | [1,2] | | 29 | [3] |
In this way, we can search by age quickly. However, the inverted index is not enough for all situations. For some fields, the number of terms would be really large. For instance, We may have a million records with different name, and if the name is not well-structured, then the efficiency for searching certain term will be very low. Thus, in order to improve the searching efficiency, we need to make the term well-structured. Let’s see how Elasticsearch does.
2.2 Term Dictionary and Term Index
In Elasticsearch, in order to search a term quickly, the terms are sorted. Then binary search can be applied in term searching. The time complexity would be O(logN), where N is the number of terms. We call it Term Dictionary. Now, compared with the traditional B+ Tree, the run complexity is almost same. (If you are not familiar with B+ tree, I will write a blog to introduce it later.) Anyway, in B+ tree, an important feature is reducing disk seeks. However, the whole term dictionary is too large to put into the memory. Then the Term Index is proposed.
Term Index is a prefix trie. The trie will not contains all terms, it just contains certain prefix with a limited hight. The leaves will point into a term dictionary. So term index looks like a table of contents for a dictionary. It shows that the location in term dictionary for terms started with certain perfix. Then the space of term index will be much smaller than the term dictionary. So the term index can be put into memory. In this way, the number of disck seek can be reduced.
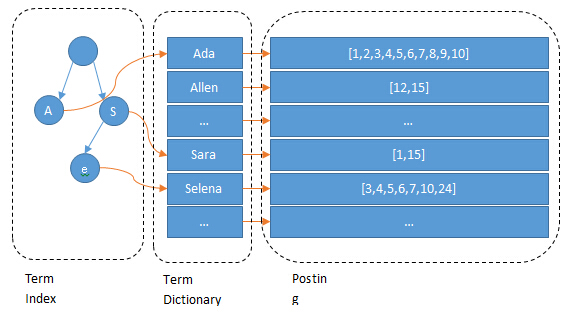
Fig 1. Term Dictionary, Term Index, and Posting List
There are still two points we need to know. One is term index is stored in Finite State Transducers (FSTs) format. FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output. (If you are not familiar with finite-state machines, I will write a blog to introduce it later.) The other is term dictionary is store in the disk by blocks, and the prefix is removed since term index already indicates their prefix. These two features will compress content and save space. Then more index can be put into memory. Now, we get the idea that content compression is important to improve searching efficiency.
Elasticsearch has two important features for compression posting list, Frame of Reference and Roaring Bitmaps, respectively. Let’s see what they are.
2.3 Frame of Reference
As we mentioned above, the posting list in term dictionary is a sorted ids. Then we can use the difference between two ids indicates the next id. The difference is less than the original id number, so we can make a small number indicates a large number. If the number is stored by bytes, the posting list in term dictionary will be compressed in disk. This compression method is called Frame of Reference.
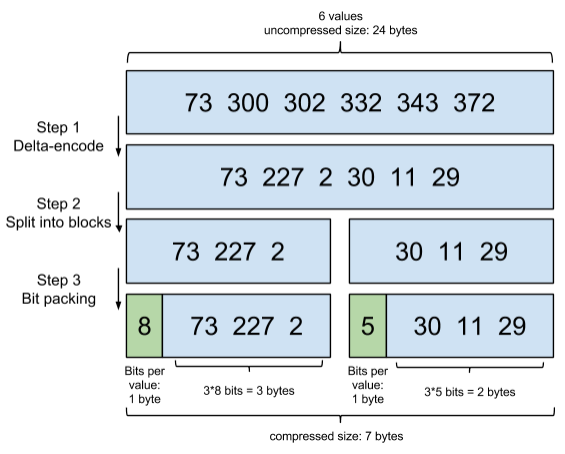
Fig 2. Frame of Reference
2.3 Roaring Bitmaps
First of all, let’s see what is bitmap. Bitmap is a mapping from some domain to bits. For instance, we have a posting list [1,3,4,7,10], the corresponding bitmap is 1011001001. We need 10 bits to represent the posting list because the maximum in the given posting list is 10, and use 0/1 to indicate whether certain value exists. However, the length of bit depends on the maximum of index in the posting list. That means we will need a million bits if we have a million records. That is a disaster. Then Roaring Bitmaps is proposed to solve this problem.
Roaring Bitmaps is a bitmap blocked with a limited length. It uses (quotient, remainder) pair to represent a id. If the posting list is blocked with 65536, when the original id in the first block is from 0 to 65536, and that in the second block is from 65536 to 131071 and so on.
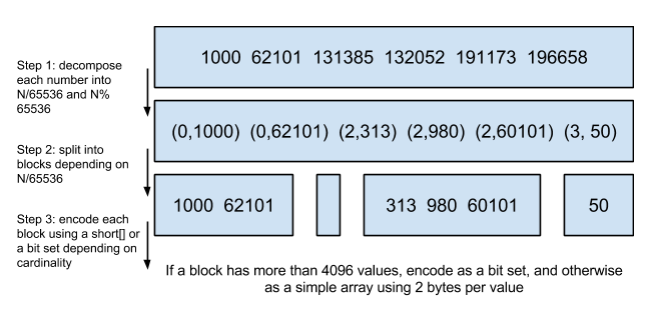
Fig 3. Roaring Bitmaps
Why Elasticsearch uses 65536 as a block? Because 65536 = 2^16, which is 2 byte and the range of short type. Please notice that in the above picture, it says “If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”. That means if there are more than 4096 ids in a block, Elasticsearch will use the roaring bitmaps. If not, it will use short array and will not compress. The reason why Elasticsearch uses 4096 is that 4096 * 2 bytes = 8192 B < 1KB. The a block will be read at least 1KB during disk seek, so all the values in the block can be got in one disk seek, and then the compress is not neccessary.

Fig 4. Roaring Bitmaps vs Bitmap in Memory
Now, we have a understanding of Elasticsearch index. I will write another blog later to introduce combination search and other features in Elasticsearch.
Reference
- https://en.wikipedia.org/wiki/Elasticsearch
- https://en.wikipedia.org/wiki/Inverted_index
- http://blog.pengqiuyuan.com/ji-chu-jie-shao-ji-suo-yin-yuan-li-fen-xi/
- http://www.infoq.com/cn/articles/database-timestamp-02?utm_source=infoq&utm_medium=related_content_link&utm_campaign=relatedContent_articles_clk
- https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps